Data iteration tools for loading into neural networks.
A dataset iterator allows for easy loading of data into neural networks and help organize batching, conversion, and masking. The iterators included in Eclipse Deeplearning4j help with either user-provided data, or automatic loading of common benchmarking datasets such as MNIST and IRIS.
For most use cases, initializing an iterator and passing a reference to a MultiLayerNetwork or ComputationGraph fit() method is all you need to begin a task for training:
Many other methods also accept iterators for tasks such as evaluation:
MNIST data set iterator - 60000 training digits, 10000 test digits, 10 classes. Digits have 28x28 pixels and 1 channel (grayscale). For futher details, see http://yann.lecun.com/exdb/mnist/
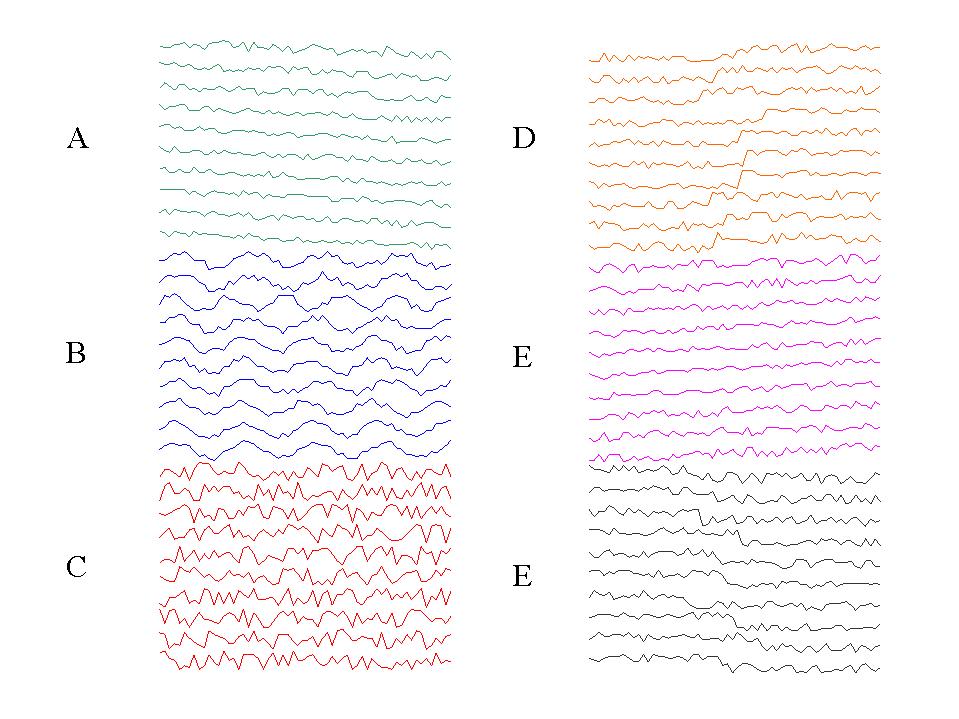
UCI synthetic control chart time series dataset. This dataset is useful for classification of univariate time series with six categories: Normal, Cyclic, Increasing trend, Decreasing trend, Upward shift, Downward shift
Details: https://archive.ics.uci.edu/ml/datasets/Synthetic+Control+Chart+Time+Series Data: https://archive.ics.uci.edu/ml/machine-learning-databases/synthetic_control-mld/synthetic_control.data Image: https://archive.ics.uci.edu/ml/machine-learning-databases/synthetic_control-mld/data.jpeg
UciSequenceDataSetIterator
Create an iterator for the training set, with the specified minibatch size. Randomized with RNG seed 123
param batchSize Minibatch size
CifarDataSetIterator is an iterator for CIFAR-10 dataset - 10 classes, with 32x32 images with 3 channels (RGB)
This fetcher uses a cached version of the CIFAR dataset which is converted to PNG images, see: https://pjreddie.com/projects/cifar-10-dataset-mirror/.
Cifar10DataSetIterator
Create an iterator for the training set, with random iteration order (RNG seed fixed to 123)
param batchSize Minibatch size for the iterator
IrisDataSetIterator: An iterator for the well-known Iris dataset. 4 features, 3 label classes https://archive.ics.uci.edu/ml/datasets/Iris
IrisDataSetIterator
next
IrisDataSetIterator handles traversing through the Iris Data Set.
param batch Batch size
param numExamples Total number of examples
LFW iterator - Labeled Faces from the Wild dataset See http://vis-www.cs.umass.edu/lfw/ 13233 images total, with 5749 classes.
LFWDataSetIterator
Create LFW data specific iterator
param batchSize the batch size of the examples
param numExamples the overall number of examples
param imgDim an array of height, width and channels
param numLabels the overall number of examples
param useSubset use a subset of the LFWDataSet
param labelGenerator path label generator to use
param train true if use train value
param splitTrainTest the percentage to split data for train and remainder goes to test
param imageTransform how to transform the image
param rng random number to lock in batch shuffling
Tiny ImageNet is a subset of the ImageNet database. TinyImageNet is the default course challenge for CS321n at Stanford University.
Tiny ImageNet has 200 classes, each consisting of 500 training images. Images are 64x64 pixels, RGB.
See: http://cs231n.stanford.edu/ and https://tiny-imagenet.herokuapp.com/
TinyImageNetDataSetIterator
Create an iterator for the training set, with random iteration order (RNG seed fixed to 123)
param batchSize Minibatch size for the iterator
EMNIST DataSetIterator
COMPLETE: Also known as 'ByClass' split. 814,255 examples total (train + test), 62 classes
MERGE: Also known as 'ByMerge' split. 814,255 examples total. 47 unbalanced classes. Combines lower and upper case characters (that are difficult to distinguish) into one class for each letter (instead of 2), for letters C, I, J, K, L, M, O, P, S, U, V, W, X, Y and Z
BALANCED: 131,600 examples total. 47 classes (equal number of examples in each class)
LETTERS: 145,600 examples total. 26 balanced classes
DIGITS: 280,000 examples total. 10 balanced classes
See: https://www.nist.gov/itl/iad/image-group/emnist-dataset and https://arxiv.org/abs/1702.05373
EmnistDataSetIterator
EMNIST dataset has multiple different subsets. See {- link EmnistDataSetIterator} Javadoc for details.
numExamplesTrain
Create an EMNIST iterator with randomly shuffled data based on a specified RNG seed
param dataSet Dataset (subset) to return
param batchSize Batch size
param train If true: use training set. If false: use test set
param seed Random number generator seed
numExamplesTest
Get the number of test examples for the specified subset
param dataSet Subset to get
return Number of examples for the specified subset
numLabels
Get the number of labels for the specified subset
param dataSet Subset to get
return Number of labels for the specified subset
isBalanced
Get the labels as a character array
return Labels
DataSet objects as well as producing minibatches from individual records.
RecordReaderDataSetIterator
Constructor for classification, where: (a) the label index is assumed to be the very last Writable/column, and (b) the number of classes is inferred from RecordReader.getLabels() Note that if RecordReader.getLabels() returns null, no output labels will be produced
param recordReader Record reader to use as the source of data
param batchSize Minibatch size, for each call of .next()
setCollectMetaData
Main constructor for classification. This will convert the input class index (at position labelIndex, with integer values 0 to numPossibleLabels-1 inclusive) to the appropriate one-hot output/labels representation.
param recordReader RecordReader: provides the source of the data
param batchSize Batch size (number of examples) for the output DataSet objects
param labelIndex Index of the label Writable (usually an IntWritable), as obtained by recordReader.next()
param numPossibleLabels Number of classes (possible labels) for classification
loadFromMetaData
Load a single example to a DataSet, using the provided RecordMetaData. Note that it is more efficient to load multiple instances at once, using {- link #loadFromMetaData(List)}
param recordMetaData RecordMetaData to load from. Should have been produced by the given record reader
return DataSet with the specified example
throws IOException If an error occurs during loading of the data
loadFromMetaData
Load a multiple examples to a DataSet, using the provided RecordMetaData instances.
param list List of RecordMetaData instances to load from. Should have been produced by the record reader provided to the RecordReaderDataSetIterator constructor
return DataSet with the specified examples
throws IOException If an error occurs during loading of the data
writableConverter
Builder class for RecordReaderDataSetIterator
maxNumBatches
Optional argument, usually not used. If set, can be used to limit the maximum number of minibatches that will be returned (between resets). If not set, will always return as many minibatches as there is data available.
param maxNumBatches Maximum number of minibatches per epoch / reset
regression
Use this for single output regression (i.e., 1 output/regression target)
param labelIndex Column index that contains the regression target (indexes start at 0)
regression
Use this for multiple output regression (1 or more output/regression targets). Note that all regression targets must be contiguous (i.e., positions x to y, without gaps)
param labelIndexFrom Column index of the first regression target (indexes start at 0)
param labelIndexTo Column index of the last regression target (inclusive)
classification
Use this for classification
param labelIndex Index that contains the label index. Column (indexes start from 0) be an integer value, and contain values 0 to numClasses-1
param numClasses Number of label classes (i.e., number of categories/classes in the dataset)
preProcessor
Optional arg. Allows the preprocessor to be set
param preProcessor Preprocessor to use
collectMetaData
When set to true: metadata for the current examples will be present in the returned DataSet. Disabled by default.
param collectMetaData Whether metadata should be collected or not
The idea: generate multiple inputs and multiple outputs from one or more Sequence/RecordReaders. Inputs and outputs may be obtained from subsets of the RecordReader and SequenceRecordReaders columns (for examples, some inputs and outputs as different columns in the same record/sequence); it is also possible to mix different types of data (for example, using both RecordReaders and SequenceRecordReaders in the same RecordReaderMultiDataSetIterator). inputs and subsets.
RecordReaderMultiDataSetIterator
When dealing with time series data of different lengths, how should we align the input/labels time series? For equal length: use EQUAL_LENGTH For sequence classification: use ALIGN_END
loadFromMetaData
Load a single example to a DataSet, using the provided RecordMetaData. Note that it is more efficient to load multiple instances at once, using {- link #loadFromMetaData(List)}
param recordMetaData RecordMetaData to load from. Should have been produced by the given record reader
return DataSet with the specified example
throws IOException If an error occurs during loading of the data
loadFromMetaData
Load a multiple sequence examples to a DataSet, using the provided RecordMetaData instances.
param list List of RecordMetaData instances to load from. Should have been produced by the record reader provided to the SequenceRecordReaderDataSetIterator constructor
return DataSet with the specified examples
throws IOException If an error occurs during loading of the data
Sequence record reader data set iterator. Given a record reader (and optionally another record reader for the labels) generate time series (sequence) data sets. Supports padding for one-to-many and many-to-one type data loading (i.e., with different number of inputs vs.
SequenceRecordReaderDataSetIterator
Constructor where features and labels come from different RecordReaders (for example, different files), and labels are for classification.
param featuresReader SequenceRecordReader for the features
param labels Labels: assume single value per time step, where values are integers in the range 0 to numPossibleLables-1
param miniBatchSize Minibatch size for each call of next()
param numPossibleLabels Number of classes for the labels
hasNext
Constructor where features and labels come from different RecordReaders (for example, different files)
loadFromMetaData
Load a single sequence example to a DataSet, using the provided RecordMetaData. Note that it is more efficient to load multiple instances at once, using {- link #loadFromMetaData(List)}
param recordMetaData RecordMetaData to load from. Should have been produced by the given record reader
return DataSet with the specified example
throws IOException If an error occurs during loading of the data
loadFromMetaData
Load a multiple sequence examples to a DataSet, using the provided RecordMetaData instances.
param list List of RecordMetaData instances to load from. Should have been produced by the record reader provided to the SequenceRecordReaderDataSetIterator constructor
return DataSet with the specified examples
throws IOException If an error occurs during loading of the data
Async prefetching iterator wrapper for MultiDataSetIterator implementations This will asynchronously prefetch the specified number of minibatches from the underlying iterator. Also has the option (enabled by default for most constructors) to use a cyclical workspace to avoid creating INDArrays with off-heap memory that needs to be cleaned up by the JVM garbage collector.
Note that appropriate DL4J fit methods automatically utilize this iterator, so users don’t need to manually wrap their iterators when fitting a network
next
We want to ensure, that background thread will have the same thread->device affinity, as master thread
setPreProcessor
Set the preprocessor to be applied to each MultiDataSet, before each MultiDataSet is returned.
param preProcessor MultiDataSetPreProcessor. May be null.
resetSupported
Is resetting supported by this DataSetIterator? Many DataSetIterators do support resetting, but some don’t
return true if reset method is supported; false otherwise
asyncSupported
Does this DataSetIterator support asynchronous prefetching of multiple DataSet objects? Most DataSetIterators do, but in some cases it may not make sense to wrap this iterator in an iterator that does asynchronous prefetching. For example, it would not make sense to use asynchronous prefetching for the following types of iterators: (a) Iterators that store their full contents in memory already (b) Iterators that re-use features/labels arrays (as future next() calls will overwrite past contents) (c) Iterators that already implement some level of asynchronous prefetching (d) Iterators that may return different data depending on when the next() method is called
return true if asynchronous prefetching from this iterator is OK; false if asynchronous prefetching should not be used with this iterator
reset
Resets the iterator back to the beginning
shutdown
We want to ensure, that background thread will have the same thread->device affinity, as master thread
hasNext
Returns {- code true} if the iteration has more elements. (In other words, returns {- code true} if {- link #next} would return an element rather than throwing an exception.)
return {- code true} if the iteration has more elements
next
Returns the next element in the iteration.
return the next element in the iteration
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
implSpec The default implementation throws an instance of {- link UnsupportedOperationException} and performs no other action.
required to get the specified batch size.
Typically used in Spark training, but may be used elsewhere. NOTE: reset method is not supported here.
Async prefetching iterator wrapper for DataSetIterator implementations. This will asynchronously prefetch the specified number of minibatches from the underlying iterator. Also has the option (enabled by default for most constructors) to use a cyclical workspace to avoid creating INDArrays with off-heap memory that needs to be cleaned up by the JVM garbage collector.
Note that appropriate DL4J fit methods automatically utilize this iterator, so users don’t need to manually wrap their iterators when fitting a network
AsyncDataSetIterator
Create an Async iterator with the default queue size of 8
param baseIterator Underlying iterator to wrap and fetch asynchronously from
next
Create an Async iterator with the default queue size of 8
param iterator Underlying iterator to wrap and fetch asynchronously from
param queue Queue size - number of iterators to
inputColumns
Input columns for the dataset
return
totalOutcomes
The number of labels for the dataset
return
resetSupported
Is resetting supported by this DataSetIterator? Many DataSetIterators do support resetting, but some don’t
return true if reset method is supported; false otherwise
asyncSupported
Does this DataSetIterator support asynchronous prefetching of multiple DataSet objects? Most DataSetIterators do, but in some cases it may not make sense to wrap this iterator in an iterator that does asynchronous prefetching. For example, it would not make sense to use asynchronous prefetching for the following types of iterators: (a) Iterators that store their full contents in memory already (b) Iterators that re-use features/labels arrays (as future next() calls will overwrite past contents) (c) Iterators that already implement some level of asynchronous prefetching (d) Iterators that may return different data depending on when the next() method is called
return true if asynchronous prefetching from this iterator is OK; false if asynchronous prefetching should not be used with this iterator
reset
Resets the iterator back to the beginning
shutdown
We want to ensure, that background thread will have the same thread->device affinity, as master thread
batch
Batch size
return
setPreProcessor
Set a pre processor
param preProcessor a pre processor to set
getPreProcessor
Returns preprocessors, if defined
return
hasNext
Get dataset iterator record reader labels
next
Returns the next element in the iteration.
return the next element in the iteration
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
implSpec The default implementation throws an instance of {- link UnsupportedOperationException} and performs no other action.
First value in pair is the features vector, second value in pair is the labels. Supports generating 2d features/labels only
DoublesDataSetIterator
param iterable Iterable to source data from
param batchSize Batch size for generated DataSet objects
required to get a specified batch size.
Typically used in Spark training, but may be used elsewhere. NOTE: reset method is not supported here.
A wrapper for a dataset to sample from. This will randomly sample from the given dataset.
SamplingDataSetIterator
First value in pair is the features vector, second value in pair is the labels.
INDArrayDataSetIterator
param iterable Iterable to source data from
param batchSize Batch size for generated DataSet objects
This iterator detaches/migrates DataSets coming out from backed DataSetIterator, thus providing “safe” DataSets. This is typically used for debugging and testing purposes, and should not be used in general by users
WorkspacesShieldDataSetIterator
param iterator The underlying iterator to detach values from
This iterator virtually splits given MultiDataSetIterator into Train and Test parts. I.e. you have 100000 examples. Your batch size is 32. That means you have 3125 total batches. With split ratio of 0.7 that will give you 2187 training batches, and 938 test batches.
PLEASE NOTE: You can’t use Test iterator twice in a row. Train iterator should be used before Test iterator use. PLEASE NOTE: You can’t use this iterator, if underlying iterator uses randomization/shuffle between epochs.
param baseIterator
param totalBatches - total number of batches in underlying iterator. this value will be used to determine number of test/train batches
param ratio - this value will be used as splitter. should be between in range of 0.0 > X < 1.0. I.e. if value 0.7 is provided, then 70% of total examples will be used for training, and 30% of total examples will be used for testing
getTrainIterator
This method returns train iterator instance
return
next
This method returns test iterator instance
return
This wrapper takes your existing DataSetIterator implementation and prevents asynchronous prefetch This is mainly used for debugging purposes; generally an iterator that isn’t safe to asynchronously prefetch from
AsyncShieldDataSetIterator
param iterator Iterator to wrop, to disable asynchronous prefetching for
next
Like the standard next method but allows a customizable number of examples returned
param num the number of examples
return the next data applyTransformToDestination
inputColumns
Input columns for the dataset
return
totalOutcomes
The number of labels for the dataset
return
resetSupported
Is resetting supported by this DataSetIterator? Many DataSetIterators do support resetting, but some don’t
return true if reset method is supported; false otherwise
asyncSupported
Does this DataSetIterator support asynchronous prefetching of multiple DataSet objects?
PLEASE NOTE: This iterator ALWAYS returns FALSE
return true if asynchronous prefetching from this iterator is OK; false if asynchronous prefetching should not be used with this iterator
reset
Resets the iterator back to the beginning
batch
Batch size
return
setPreProcessor
Set a pre processor
param preProcessor a pre processor to set
getPreProcessor
Returns preprocessors, if defined
return
hasNext
Get dataset iterator record reader labels
next
Returns the next element in the iteration.
return the next element in the iteration
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
implSpec The default implementation throws an instance of {- link UnsupportedOperationException} and performs no other action.
This class provides baseline implementation of BlockDataSetIterator interface
Baseline implementation includes control over the data fetcher and some basic getters for metadata
This wrapper takes your existing MultiDataSetIterator implementation and prevents asynchronous prefetch
next
Fetch the next ‘num’ examples. Similar to the next method, but returns a specified number of examples
param num Number of examples to fetch
setPreProcessor
Set the preprocessor to be applied to each MultiDataSet, before each MultiDataSet is returned.
param preProcessor MultiDataSetPreProcessor. May be null.
resetSupported
Is resetting supported by this DataSetIterator? Many DataSetIterators do support resetting, but some don’t
return true if reset method is supported; false otherwise
asyncSupported
/ Does this DataSetIterator support asynchronous prefetching of multiple DataSet objects?
PLEASE NOTE: This iterator ALWAYS returns FALSE
return true if asynchronous prefetching from this iterator is OK; false if asynchronous prefetching should not be used with this iterator
reset
Resets the iterator back to the beginning
hasNext
Returns {- code true} if the iteration has more elements. (In other words, returns {- code true} if {- link #next} would return an element rather than throwing an exception.)
return {- code true} if the iteration has more elements
next
Returns the next element in the iteration.
return the next element in the iteration
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
implSpec The default implementation throws an instance of {- link UnsupportedOperationException} and performs no other action.
RandomMultiDataSetIterator: Generates random values (or zeros, ones, integers, etc) according to some distribution. Note: This is typically used for testing, debugging and benchmarking purposes.
RandomMultiDataSetIterator
param numMiniBatches Number of minibatches per epoch
param features Each triple in the list specifies the shape, array order and type of values for the features arrays
param labels Each triple in the list specifies the shape, array order and type of values for the labels arrays
addFeatures
param numMiniBatches Number of minibatches per epoch
addFeatures
Add a new features array to the iterator
param shape Shape of the features
param order Order (‘c’ or ‘f’) for the array
param values Values to fill the array with
addLabels
Add a new labels array to the iterator
param shape Shape of the features
param values Values to fill the array with
addLabels
Add a new labels array to the iterator
param shape Shape of the features
param order Order (‘c’ or ‘f’) for the array
param values Values to fill the array with
generate
Generate a random array with the specified shape
param shape Shape of the array
param values Values to fill the array with
return Random array of specified shape + contents
generate
Generate a random array with the specified shape and order
param shape Shape of the array
param order Order of array (‘c’ or ‘f’)
param values Values to fill the array with
return Random array of specified shape + contents
Builds an iterator that terminates once the number of minibatches returned with .next() is equal to a specified number. Note that a call to .next(num) is counted as a call to return a minibatch regardless of the value of num This essentially restricts the data to this specified number of minibatches.
EarlyTerminationMultiDataSetIterator
Constructor takes the iterator to wrap and the number of minibatches after which the call to hasNext() will return false
param underlyingIterator, iterator to wrap
param terminationPoint, minibatches after which hasNext() will return false
ExistingDataSetIterator
Note that when using this constructor, resetting is not supported
param iterator Iterator to wrap
next
Note that when using this constructor, resetting is not supported
param iterator Iterator to wrap
param labels String labels. May be null.
This class provides baseline implementation of BlockMultiDataSetIterator interface
Builds an iterator that terminates once the number of minibatches returned with .next() is equal to a specified number. Note that a call to .next(num) is counted as a call to return a minibatch regardless of the value of num This essentially restricts the data to this specified number of minibatches.
EarlyTerminationDataSetIterator
Constructor takes the iterator to wrap and the number of minibatches after which the call to hasNext() will return false
param underlyingIterator, iterator to wrap
param terminationPoint, minibatches after which hasNext() will return false
Wraps a data set iterator setting the first (feature matrix) as the labels.
next
Like the standard next method but allows a customizable number of examples returned
param num the number of examples
return the next data applyTransformToDestination
inputColumns
Input columns for the dataset
return
totalOutcomes
The number of labels for the dataset
return
reset
Resets the iterator back to the beginning
batch
Batch size
return
hasNext
Returns {- code true} if the iteration has more elements. (In other words, returns {- code true} if {- link #next} would return an element rather than throwing an exception.)
return {- code true} if the iteration has more elements
next
Returns the next element in the iteration.
return the next element in the iteration
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
This iterator virtually splits given MultiDataSetIterator into Train and Test parts. I.e. you have 100000 examples. Your batch size is 32. That means you have 3125 total batches. With split ratio of 0.7 that will give you 2187 training batches, and 938 test batches.
PLEASE NOTE: You can’t use Test iterator twice in a row. Train iterator should be used before Test iterator use. PLEASE NOTE: You can’t use this iterator, if underlying iterator uses randomization/shuffle between epochs.
DataSetIteratorSplitter
The only constructor
param baseIterator - iterator to be wrapped and split
param totalBatches - total batches in baseIterator
param ratio - train/test split ratio
getTrainIterator
This method returns train iterator instance
return
next
This method returns test iterator instance
return
This dataset iterator combines multiple DataSetIterators into 1 MultiDataSetIterator. Values from each iterator are joined on a per-example basis - i.e., the values from each DataSet are combined as different feature arrays for a multi-input neural network. Labels can come from either one of the underlying DataSetIteartors only (if ‘outcome’ is >= 0) or from all iterators (if outcome is < 0)
JointMultiDataSetIterator
param iterators Underlying iterators to wrap
next
param outcome Index to get the label from. If < 0, labels from all iterators will be used to create the final MultiDataSet
param iterators Underlying iterators to wrap
setPreProcessor
Set the preprocessor to be applied to each MultiDataSet, before each MultiDataSet is returned.
param preProcessor MultiDataSetPreProcessor. May be null.
getPreProcessor
Get the {- link MultiDataSetPreProcessor}, if one has previously been set. Returns null if no preprocessor has been set
return Preprocessor
resetSupported
Is resetting supported by this DataSetIterator? Many DataSetIterators do support resetting, but some don’t
return true if reset method is supported; false otherwise
asyncSupported
Does this MultiDataSetIterator support asynchronous prefetching of multiple MultiDataSet objects? Most MultiDataSetIterators do, but in some cases it may not make sense to wrap this iterator in an iterator that does asynchronous prefetching. For example, it would not make sense to use asynchronous prefetching for the following types of iterators: (a) Iterators that store their full contents in memory already (b) Iterators that re-use features/labels arrays (as future next() calls will overwrite past contents) (c) Iterators that already implement some level of asynchronous prefetching (d) Iterators that may return different data depending on when the next() method is called
return true if asynchronous prefetching from this iterator is OK; false if asynchronous prefetching should not be used with this iterator
reset
Resets the iterator back to the beginning
hasNext
Returns {- code true} if the iteration has more elements. (In other words, returns {- code true} if {- link #next} would return an element rather than throwing an exception.)
return {- code true} if the iteration has more elements
next
Returns the next element in the iteration.
return the next element in the iteration
remove
PLEASE NOTE: This method is NOT implemented
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
implSpec The default implementation throws an instance of {- link UnsupportedOperationException} and performs no other action.
First value in pair is the features vector, second value in pair is the labels. Supports generating 2d features/labels only
FloatsDataSetIterator
param iterable Iterable to source data from
param batchSize Batch size for generated DataSet objects
Simple iterator working with list of files. File to DataSet conversion will be handled via provided FileCallback implementation
FileSplitDataSetIterator
param files List of files to iterate over
param callback Callback for loading the files
A dataset iterator for doing multiple passes over a dataset
Use MultiLayerNetwork/ComputationGraph.fit(DataSetIterator, int numEpochs) instead
next
Like the standard next method but allows a customizable number of examples returned
param num the number of examples
return the next data applyTransformToDestination
inputColumns
Input columns for the dataset
return
totalOutcomes
The number of labels for the dataset
return
reset
Resets the iterator back to the beginning
batch
Batch size
return
hasNext
Returns {- code true} if the iteration has more elements. (In other words, returns {- code true} if {- link #next} would return an element rather than throwing an exception.)
return {- code true} if the iteration has more elements
remove
Removes from the underlying collection the last element returned by this iterator (optional operation). This method can be called only once per call to {- link #next}. The behavior of an iterator is unspecified if the underlying collection is modified while the iteration is in progress in any way other than by calling this method.
throws UnsupportedOperationException if the {- code remove} operation is not supported by this iterator
throws IllegalStateException if the {- code next} method has not yet been called, or the {- code remove} method has already been called after the last call to the {- code next} method
This class is simple wrapper that takes single-input MultiDataSets and converts them to DataSets on the fly
PLEASE NOTE: This only works if number of features/labels/masks is 1
MultiDataSetWrapperIterator
param iterator Undelying iterator to wrap
RandomDataSetIterator: Generates random values (or zeros, ones, integers, etc) according to some distribution. Note: This is typically used for testing, debugging and benchmarking purposes.
RandomDataSetIterator
param numMiniBatches Number of minibatches per epoch
param featuresShape Features shape
param labelsShape Labels shape
param featureValues Type of values for the features
param labelValues Type of values for the labels
Iterator that adapts a DataSetIterator to a MultiDataSetIterator
{kind=link}