Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Toy datasets are essential for testing hypotheses and getting started with any neural network training process. Deeplearning4j comes with built-in dataset iterators for common datasets, including but not limited to:
MNIST
Iris
TinyImageNet (subset of ImageNet)
CIFAR-10
Labelled Faces in the Wild
Curve Fragment Ground-Truth Dataset
These datasets are also used as a baseline for testing other machine learning algorithms. Please remember to use these datasets correctly within the terms of their license (for example, you must obtain special permission to use ImageNet in a commercial project).
Building on what we know about MultiLayerNetwork and ComputationGraph, we will instantiate a couple data iterators to feed a toy dataset into a neural network for training. This tutorial is focused on training a classifier (you can also train networks for regression, or use them for unsupervised training via an autoencoder), and you will also learn how to interpret the output in the console.
A MultiLayerNetwork can classify MNIST digits. If you are not familiar with MNIST, it is a dataset originally assembled for recognizing hand-written numerals. You can read more about MNIST here.
Once you have imported what you need, set up a basic MultiLayerNetwork like below.
The MNIST iterator, like most of Deeplearning4j’s built-in iterators, extends the DataSetIterator class. This API allows for simple instantiation of datasets and automatic downloading of data in the background. The MNIST data iterator API specifically allows you to specify whether you are using the training or testing dataset, so instantiate two different iterators to evaluate your network.
Now that the network configuration is set up and instantiated along with our MNIST test/train iterators, training takes just a few lines of code. The fun begins.
Earlier we attached a ScoreIterationListener to the model by using the setListeners() method. Depending on the browser you are using to run this notebook, you can open the debugger/inspector to view listener output. This output is redirected to the console since the internals of Deeplearning4j use SLF4J for logging, and the output is being redirected by Zeppelin. This is a good thing since it can reduce clutter in notebooks.
As a well-tuned model continues to train, its error score will decrease with each iteration. This error or loss score will eventually converge to a value close to zero. Note that more complex networks and problems may never yield an optimal score. This is where you need to become the expert and continue to tune and change your model’s configuration.
“Overfitting” is a common problem in deep learning where your model doesn’t generalize well to the problem you are trying to solve. This can happen when you have run the algorithm for too many epochs over a training dataset, when you haven’t used a regularization technique like Dropout, or the training dataset isn’t big enough and doesn’t encapsulate all of the features that are descriptive of your classes in the real world.
Deeplearning4j comes with built-in tools for model evaluation. The simplest is to pass a testing iterator to eval() and retrieve an Evaluation object. Many more, including ROC plotting and regression evaluation, are available in the org.nd4j.evaluation.classification package.
With deep learning, we can compose a deep neural network to suit the input data and its features. The goal is to train the network on the data to make predictions, and those predictions are tied to the outcomes that you care about; i.e. is this transaction fraudulent or not, or which object is contained in the photo? There are different techniques to configure a neural network, and all of them build a relational hierarchy between the inputs and outputs.
In this tutorial, we are going to configure the simplest neural network and that is logistic regression model network.
Regression is a process that helps show the relations between the independent variables (inputs) and the dependent variables (outputs). Logistic regression is one in which the dependent variable is categorical rather than continuous - meaning that it can predict only a limited number of classes or categories, like a switch you flip on or off. For example, it can predict that an image contains a cat or a dog, or it can classify input in ten buckets with the integers 0 through 9.
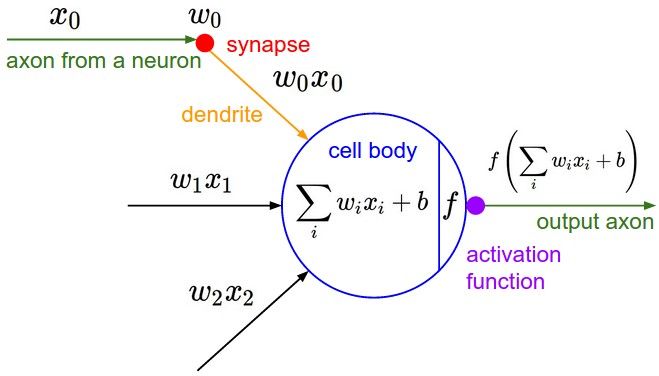
A simple logistic regression calculates x*w + b = y. Where x is an instance of input data, w is the weight or coefficient that transforms that input, b is the bias and y is the output, or prediction about the data. The biological terms show how this artificial neuron loosely maps to a neuron in the human brain. The most important point is how data flows through and is transformed by this structure.
We’re going to configure the simplest network, with just one input layer and one output layer, to show how logistic regression works.
We are going to first build the layers and then feed these layers into the network configuration.
You may be wondering why didn’t we write any code for building our input layer. The input layer is only a set of inputs values fed into the network. It doesn’t perform a calculation. It’s just an input sequence (raw or pre-processed data) coming into the network, data to be trained on or to be evaluated. Later, we are going to work with data iterators, which feed input to a network in a specific pattern, and which can be thought of as an input layer of the network.
Anomaly Detection Using Reconstruction Error
Why use an autoencoder? In practice, autoencoders are often applied to data denoising and dimensionality reduction. This works great for representation learning and a little less great for data compression.
In deep learning, an autoencoder is a neural network that “attempts” to reconstruct its input. It can serve as a form of feature extraction, and autoencoders can be stacked to create “deep” networks. Features generated by an autoencoder can be fed into other algorithms for classification, clustering, and anomaly detection.
Autoencoders are also useful for data visualization when the raw input data has high dimensionality and cannot easily be plotted. By lowering the dimensionality, the output can sometimes be compressed into a 2D or 3D space for better data exploration.
Autoencoders are comprised of:
Encoding function (the “encoder”)
Decoding function (the “decoder”)
Distance function (a “loss function”)
An input is fed into the autoencoder and turned into a compressed representation. The decoder then learns how to reconstruct the original input from the compressed representation, where during an unsupervised training process, the loss function helps to correct the error produced by the decoder. This process is automatic (hence “auto”-encoder); i.e. it does not require human intervention.
Now that you know how to create different network configurations with MultiLayerNetwork and ComputationGraph, we will construct a “stacked” autoencoder that performs anomaly detection on MNIST digits without pretraining. The goal is to identify outlier digits; i.e. digits that are unusual and atypical. Identification of items, events or observations that “stand out” from the norm of a given dataset is broadly known as anomaly detection. Anomaly detection does not require a labeled dataset, and can be undertaken with unsupervised learning, which is helpful because most of the world’s data is not labeled.
This type of anomaly detection uses reconstruction error to measure how well the decoder is performing. Stereotypical examples should have low reconstruction error, whereas outliers should have high reconstruction error.
Network intrusion, fraud detection, systems monitoring, sensor network event detection (IoT), and unusual trajectory sensing are examples of anomaly detection applications.
The following autoencoder uses two stacked dense layers for encoding. The MNIST digits are transformed into a flat 1D array of length 784 (MNIST images are 28x28 pixels, which equals 784 when you lay them end to end).
784 → 250 → 10 → 250 → 784
The MNIST iterator, like most of Deeplearning4j’s built-in iterators, extends the DataSetIterator class. This API allows for simple instantiation of datasets and the automatic downloading of data in the background.
Now that the network configruation is set up and instantiated along with our MNIST test/train iterators, training takes just a few lines of code. The fun begins.
Earlier, we attached a ScoreIterationListener to the model by using the setListeners() method. Depending on the browser used to run this notebook, you can open the debugger/inspector to view listener output. This output is redirected to the console since the internals of Deeplearning4j use SL4J for logging, and the output is being redirected by Zeppelin. This helps reduce clutter in the notebooks.
Now that the autoencoder has been trained, we’ll evaluate the model on the test data. Each example will be scored individually, and a map will be composed that relates each digit to a list of (score, example) pairs.
Finally, we will calculate the N best and N worst scores per digit.
When training neural networks, it is important to avoid overfitting the training data. Overfitting occurs when the neural network learns the noise in the training data and thus does not generalize well to data it has not been trained on. One hyperparameter that affects whether the neural network will overfit or not is the number of epochs or complete passes through the training split. If we use too many epochs, then the neural network is likely to overfit. On the other hand, if we use too few epochs, the neural network might not have the chance to learn fully from the training data.
Early stopping is one mechanism used to manually set the number of epochs to prevent underfitting and overfitting. The idea behind early stopping is intuitive. First the data is split into training and testing sets. At the end of each epoch, the neural network is evaluated on the test set. If the neural network outperforms the previous best model, then we save the neural network. The best overall model is then taken to be the final model.
In this tutorial we will show how to use early stopping with deeplearning4j (DL4J). We will apply the method on a feed forward neural network using the MNIST dataset, which is a dataset consisting of handwritten digits.
Now that we have imported everything needed to run this tutorial, we can start by setting the parameters for the neural network and initializing the data. We will set the maximum number of epochs to run early stopping on to be 15.
Next we will set the neural network configuration using the MultiLayerNetwork class of DL4J and initialize the MultiLayerNetwork.
If we weren’t using early stopping, we would proceed by training the neural network using for loops and the fit method of the MultiLayerNetwork. But since we are using early stopping we need to configure how early stopping will be applied. Looking at the next cell, we will use a maximum epoch number of 10 and a maximum training time of 5 minutes. The evaluation will be done on mnistTest after each epoch. Each model will be saved in the DL4JEarlyStoppingExample directory that we specified.
Once the EarlyStoppingConfiguration is specified, we only need to initialize an EarlyStoppingTrainer using the training data and the two previous configuraitons. The results are obtained just by calling the fit method of EarlyStoppingTrainer.
We can then print out the details of the best model.
DL4J provides the following classes to configure networks:
MultiLayerNetwork
ComputationGraph
MultiLayerNetwork consists of a single input layer and a single output layer with a stack of layers in between them.
ComputationGraph is used for constructing networks with a more complex architecture than MultiLayerNetwork. It can have multiple input layers, multiple output layers and the layers in between can be connected through a direct acyclic graph.
Whether you create MultiLayerNetwork or ComputationGraph, you have to provide a network configuration to it through NeuralNetConfiguration.Builder. As the name implies, it provides a Builder pattern to configure a network. To create a MultiLayerNetwork, we build a MultiLayerConfiguraionand for ComputationGraph, it’s ComputationGraphConfiguration.
The pattern goes like this: [High Level Configuration] -> [Configure Layers] -> [Build Configuration]
Function
Details
seed
For keeping the network outputs reproducible during runs by initializing weights and other network randomizations through a seed
updater
Algorithm to be used for updating the parameters. The first value is the learning rate, the second one is the Nesterov's momentum.
Here we are calling list() to get the ListBuilder. It provides us the necessary api to add layers to the network through the layer(arg1, arg2) function.
The first parameter is the index of the position where the layer needs to be added.
The second parameter is the type of layer we need to add to the network.
To build and add a layer we use a similar builder pattern as:
Function
Details
nIn
The number of inputs coming from the previous layer. (In the first layer, it represents the input it is going to take from the input layer)
nOut
he number of outputs it’s going to send to the next layer. (For output layer it represents the labels here)
weightInit
The type of weights initialization to use for the layer parameters.
activation
The activation function between layers
Finally, the last build() call builds the configuration for us.
You can get your network configuration as String, JSON or YAML for sanity checking. For JSON we can use the toJson() function.
Finally, to create a MultiLayerNetwork, we pass the configuration to it as shown below
The only difference here is the way we are building layers. Instead of calling the list() function, we call the graphBuilder() to get a GraphBuilder for building our ComputationGraphConfiguration. Following table explains what each function of a GraphBuilder does.
Function
Details
addInputs
A list of strings telling the network what layers to use as input layers
addLayer
First parameter is the layer name, then the layer object and finally a list of strings defined previously to feed this layer as inputs
setOutputs
A list of strings telling the network what layers to use as output layers
The output layers defined here use another function lossFunction to define what loss function to use.
You can get your network configuration as String, JSON or YAML for sanity checking. For JSON we can use the toJson() function
Finally, to create a ComputationGraph, we pass the configuration to it as shown below
with Skip Connections
Sequence Classification Of Synthetic Control Data
Recurrent neural networks (RNN’s) are used when the input is sequential in nature. Typically RNN’s are much more effective than regular feed forward neural networks for sequential data because they can keep track of dependencies in the data over multiple time steps. This is possible because the output of a RNN at a time step depends on the current input and the output of the previous time step.
RNN’s can also be applied to situations where the input is sequential but the output isn’t. In these cases the output of the last time step of the RNN is typically taken as the output for the overall observation. For classification, the output of the last time step will be the predicted class label for the observation.
In this tutorial we will show how to build a RNN using the MultiLayerNetwork class of deeplearning4j (DL4J). This tutorial will focus on applying a RNN for a classification task. We will be using the MNIST data, which is a dataset that consists of images of handwritten digits, as the input for the RNN. Although the MNIST data isn’t time series in nature, we can interpret it as such since there are 784 inputs. Thus, each observation or image will be interpreted to have 784 time steps consisting of one scalar value for a pixel. Note that we use a RNN for this task for purely pedagogical reasons. In practice, convolutional neural networks (CNN’s) are better suited for image classification tasks.
UCI has a number of datasets available for machine learning, make sure you have enough space on your local disk. The UCI synthetic control dataset can be found at http://archive.ics.uci.edu/ml/datasets/synthetic+control+chart+time+series. The code below will check if the data already exists and download the file.
Now that we’ve saved our dataset to a CSV sequence format, we need to set up a CSVSequenceRecordReader and iterator that will read our saved sequences and feed them to our network. If you have already saved your data to disk, you can run this code block (and remaining code blocks) as much as you want without preprocessing the dataset again. Convenient!
Once everything needed is imported we can jump into the code. To build the neural network, we can use a set up like what is shown below. Because there are 784 timesteps and 10 class labels, nIn is set to 784 and nOut is set to 10 in the MultiLayerNetwork configuration.
To train the model, pass the training iterator to the model’s fit() method. We can pass the number of epochs or passes through the training data directly to the fit() method.
Once training is complete we only a couple lines of code to evaluate the model on a test set. Using a test set to evaluate the model typically needs to be done in order to avoid overfitting on the training data. If we overfit on the training data, we have essentially fit to the noise in the data.
An Evaluation class has more built-in methods if you need to extract a confusion matrix, and other tools are also available for calculating the Area Under Curve (AUC).
Training neural network models can be a computationally expensive task. In order to speed up the training process, you can choose to train your models in parallel with multiple GPU’s if they are installed on your machine. With deeplearning4j (DL4J), this isn’t a difficult thing to do. In this tutorial we will use the MNIST dataset (dataset of handwritten images) to train a feed forward neural network in parallel with multiple GPUs.
Note: This also works if you can't fully load your CPU. In that case you just stay with the CPU specific backend.
You must have multiple CUDA compatible GPUs, ideally of the same speed
You must setup your project to use the CUDA Backend, for help see Backends
To obtain the data, we use built-in DataSetIterators for the MNIST with a random seed of 12345. These DataSetIterators can be used to directly feed the data into a neural network.
Next, we set up the neural network configuration using a convolutional configuration and initialize the model.
Next we need to configure the parallel training with the ParallelWrapper class using the MultiLayerNetwork as the input. The ParallelWrapper will take care of load balancing between different GPUs.
The notion is that the model will be duplicated within the ParallelWrapper. The prespecified number of workers (in this case 2) will then train its own model using its data. After a specified number of iterations (in this case 3), all models will be averaged and workers will receive duplicate models. The training process will then continue in this way until the model is fully trained.
To train the model, the fit method of the ParallelWrapper is used directly on the DataSetIterator. Because the ParallelWrapper class handles all the training details behind the scenes, it is very simple to parallelize this process using dl4j.
Neural network hyperparameters are parameters set prior to training. They include the learning rate, batch size, number of epochs, regularization, weight initialization, number of hidden layers, number of nodes, and etc. Unlike the weights and biases of the nodes of the neural network, they cannot be estimated directly using the data. Setting an optimal or near-optimal configuration of the hyperparameters can significantly affect neural network performance. Thus, time should be set aside to tune these hyperparameters. Deeplearning4j (DL4J) provides functionality to do exactly this task. Arbiter was created explicitly for tuning neural network models and is part of the DL4J suite of deep learning tools. In this tutorial, we will show an example of using Arbiter to tune the learning rate and the number of hidden nodes or layer size of a neural network model. We will use the MNIST dataset (images of handwritten digits) to train the neural network.
Our goal of this tutorial is to tune the learning rate and the layer size. We can start by setting up the parameter space of the learning rate and the layer size. We will consider values between 0.0001 and 0.1 for the learning rate and integer values between 16 and 256 for the layer size.
Next, we set up a MultiLayerSpace, which is similar in structure to the MultiLayerNetwork class we’ve seen below. Here, we can set the hyperparameters of the neural network model. However, we can set the learning rate and the number of hidden nodes using the ParameterSpaces we’ve initialized before and not a set value like the other hyperparameters.
Lastly, we use the CandidateGenerator class to configure how candidate values of the learning rate and the layer size will be generated. In this tutorial, we will use random search; thus, values for the learning rate and the layer size will be generated uniformly within their ranges.
To obtain the data, we will use the built-in MnistDataProvider class and use two training epochs or complete passes through the data and a batch size of 64 for training.
We’ve set how we are going to generate new values of the two hyperparameters we are considering but there still remains the question of how to evaluate them. We will use the accuracy score metric to evaluate different configurations of the hyperparameters so we initialize a EvaluationScoreFunction.
We also want to set how long the hyperparameter search will last. There are infinite configurations of the learning rate and hidden layer size, since the learning rate space is continuous. Thus, we set a termination condition of 15 minutes.
To save the best model, we can set the directory to save it in.
Given all the configurations we have already set, we need to put them together using the OptimizationConfiguration. To execute the hyperparameter search, we initialize an IOptimizaitonRunner using the OptimizationConfiguration.
Lastly, we can print out the details of the best model and the results.
In our previous tutorial, we learned about a very simple neural network model - the logistic regression model. Although you can solve many tasks with a simple model like that, most of the problems require a much complex network configuration. Typical Deep leaning model consists of many layers between the inputs and outputs. In this tutorial, we are going to learn about one of those configuration i.e. Feed-forward neural networks.
Feed-forward networks are those in which there is not cyclic connection between the network layers. The input flows forward towards the output after going through several intermediate layers. A typical feed-forward network looks like this:
Here you can see a different layer named as a hidden layer. The layers in between our input and output layers are called hidden layers. It’s called hidden because we don’t directly deal with them and hence not visible. There can be more than one hidden layer in the network.
Just as our softmax activation after our output layer in the previous tutorial, there can be activation functions between each layer of the network. They are responsible to allow (activate) or disallow our network output to the next layer node. There are different activation functions such as sigmoid and relu etc.
As you can see above that we have made a feed-forward network configuration with one hidden layer. We have used a RELU activation between our hidden and output layer. RELUs are one of the most popularly used activation functions. Activation functions also introduce non-linearities in our network so that we can learn on more complex features present in our data. Hidden layers can learn features from the input layer and it can send those features to be analyzed by our output layer to get the corresponding outputs. You can similarly make network configurations with more hidden layers as:
Deeplearning4j - also known as “DL4J” - is a high performance domain-specific language to configure deep neural networks, which are made of multiple layers. Deeplearning4j is open source, written in C++, Java, Scala, and Python, and maintained by the Eclipse Foundation & community contributors.
If you are having difficulty, we recommend you join our community forums. There you can request help and give feedback, but please do use this guide before asking questions we’ve answered below. If you are new to deep learning, we’ve included a road map for beginners with links to courses, readings and other resources. For a longer and more detailed version of this guide, please visiting the Deeplearning4j Getting Started guide.
In this quickstart, you will create a deep neural network using Deeplearning4j and train a model capable of classifying random handwriting digits. While handwriting recognition has been attempted by different machine learning algorithms over the years, deep learning performs remarkably well and achieves an accuracy of over 99.7% on the MNIST dataset. For this tutorial, we will classify digits in EMNIST, the “next generation” of MNIST and a larger dataset.
Load a dataset for a neural network.
Format EMNIST for image recognition.
Create a deep neural network.
Train a model.
Evaluate the performance of your model.
Like most programming languages, you need to explicitly import the classes you want to use into scope. Below, we will import common Deeplearning4j classes that will help us configure and train a neural network. The code below is written in Scala.
Note we import methods from Scala’s JavaConversions class because this will allow us to use native Scala collections while maintaining compatibility with Deeplearning4j’s Java collections.
Dataset iterators are important pieces of code that help batch and iterate across your dataset for training and inferring with neural networks. Deeplearning4j comes with a built-in implementation of a BaseDatasetIterator for EMNIST known as EmnistDataSetIterator. This particular iterator is a convenience utility that handles downloading and preparation of data.
Note that we create two different iterators below, one for training data and the other for for evaluating the accuracy of our model after training. The last boolean parameter in the constructor indicates whether we are instantiating test/train.
You won’t need it for this tutorial, you can learn more about loading data for neural networks in this ETL user guide. DL4J comes with many record readers that can load and convert data into ND-Arrays from CSVs, images, videos, audio, and sequences.
For any neural network you build in Deeplearning4j, the foundation is the NeuralNetConfiguration class. This is where you configure hyperparameters, the quantities that define the architecture and how the algorithm learns. Intuitively, each hyperparameter is like one ingredient in a meal, a meal that can go very right, or very wrong… Luckily, you can adjust hyperparameters if they don’t produce the right results.
The list() method specifies the number of layers in the net; this function replicates your configuration n times and builds a layerwise configuration.
Each node (the circles) in the hidden layer represents a feature of a handwritten digit in the MNIST dataset. For example, imagine you are looking at the number 6. One node may represent rounded edges, another node may represent the intersection of curly lines, and so on and so forth. Such features are weighted by importance by the model’s coefficients, and recombined in each hidden layer to help predict whether the handwritten number is indeed 6. The more layers of nodes you have, the more complexity and nuance they can capture to make better predictions.
You could think of a layer as “hidden” because, while you can see the input entering a net, and the decisions coming out, it’s difficult for humans to decipher how and why a neural net processes data on the inside. The parameters of a neural net model are simply long vectors of numbers, readable by machines.
Now that we’ve built a NeuralNetConfiguration, we can use the configuration to instantiate a MultiLayerNetwork. When we call the init() method on the network, it applies the chosen weight initialization across the network and allows us to pass data to train. If we want to see the loss score during training, we can also pass a listener to the network.
An instantiated model has a fit() method that accepts a dataset iterator (an iterator that extends BaseDatasetIterator), a single DataSet, or an ND-Array (an implementation of INDArray). Since our EMNIST iterator already extends the iterator base class, we can pass it directly to fit. If we want to train for multiple epochs, put the number of total epochs in the second argument of fit() method.
Deeplearning4j exposes several tools to evaluate the performance of a model. You can perform basic evaluation and get metrics such as precision and accuracy, or use a Receiver Operating Characteristic (ROC). Note that the general ROC class works for binary classifiers, whereas ROCMultiClass is meant for classifiers such as the model we are building here.
A MultiLayerNetwork conveniently has a few methods built-in to help us perform evaluation. You can pass a dataset iterator with your testing/validation data to an evaluate() method.
Now that you’ve learned how to get started and train your first model, head to the Deeplearning4j website to see all the other tutorials that await you. Learn how to build dataset iterators, train a facial recognition network like FaceNet, and more.
Deeplearning4j Tutorials
While Deeplearning4j is written in Java, the Java Virtual Machine (JVM) lets you import and share code in other JVM languages. These tutorials are written in Scala, the de facto standard for data science in the Java environment. There’s nothing stopping you from using any other interpreter such as Java, Kotlin, or Clojure.
If you’re coming from non-JVM languages like Python or R, you may want to read about how the JVM works before using these tutorials. Knowing the basic terms such as classpath, virtual machine, “strongly-typed” languages, and functional programming will help you debug, as well as expand on the knowledge you gain here. If you don’t know Scala and want to learn it, Coursera has a great course named Functional Programming Principles in Scala.
The tutorials are currently being reworked. You will likely find stumbling points. If you need any support while working through them, feel free to ask questions on https://community.konduit.ai/.
Trajectory Clustering Using AIS
This tutorial still uses an outdated API version. You can still get an idea of how things work, but you will not be able to copy & paste code from it without modifications.
Sometimes, deep learning is just one piece of the whole project. You may have a time series problem requiring advanced analysis and you need to use more than just a neural network. Trajectory clustering can be a difficult problem to solve when your data isn’t quite “even”. Marine Automatic Identification System (AIS) is an open system for marine broadcasting of positions. It primarily helps collision avoidance and marine authorities to monitor marine traffic.
What if you wanted to determine the most popular routes? Or take it one step further and identify anomalous traffic? Not everything can be done with a single neural network. Furthermore, AIS data for 1 year is over 100GB compressed. You’ll need more than just a desktop computer to analyze it seriously.
As you learned in the Basic Autoencoder tutorial, applications of autoencoders in data science include dimensionality reduction and data denoising. Instead of using dense layers in an autoencoder, you can swap out simple MLPs for LSTMs. That same network using LSTMs are sequence-to-sequence autoencoders and are effective at capturing temporal structure.
In the case of AIS data, coordinates can be reported at irregular intervals over time. Not all time series for a single ship have an equal length - there’s high dimensionality in the data. Before deep learning was used, other techniques like dynamic time warping were used for measuring similarity between sequences. However, now that we can train a network to compress a trajectory of a ship using a seq2seq autoencoder, we can use the output for various things.
So let’s say we want to group similar trajectories of ships together using all available AIS data. It’s hard to guess how many unique groups of routes exist for marine traffic, so a clustering algorithm like k-means is not useful. This is where the G-means algorithm has some utility.
G-means will repeatedly test a group for Gaussian patterns. If the group tests positive, then it will split the group. This will continue to happen until the groups no longer appear Gaussian. There are also other methods for non-K-means analysis, but G-means is quite useful for our needs.
Sometimes a single computer doesn’t cut it for munging your data. Hadoop was originally developed for storing and processing large amounts of data; however, with times comes innovation and Apache Spark was eventually developed for faster large-scale data processing, touting up to a 100x improvement over Hadoop. The two frameworks aren’t entirely identical - Spark doesn’t have its own filesystem and often uses Hadoop’s HDFS.
Spark is also capable of SQL-like exploration of data with its spark-sql module. However, it is not unique in the ecosystem and other frameworks such as Hive and Pig have similar functionality. At the conceptual level, Hive and Pig make it easy to write map-reduce programs. However, Spark has largely become the de facto standard for data analysis and Pig has recently introduced a Spark integration.
Using Deeplearning4j, DataVec, and some custom code you will learn how to cluster large amounts of AIS data. We will be using a local Spark cluster built-in to Zeppelin to execute DataVec preprocessing, train an autoencoder on the converted sequences, and finally use G-means on the compressed output and visualize the groups.
The file we will be downloading is nearly 2GB uncompressed, make sure you have enough space on your local disk. If you want to check out the file yourself, you can download a copy from https://dl4jdata.blob.core.windows.net/datasets/aisdk_20171001.csv.zip. The code below will check if the data already exists and download the file.
The trouble with raw data is that it usually doesn’t have the clean structure that you would expect for an example. It’s useful to investigate the structure of the data, calculate some basic statistics on average sequence length, and figure out the complexity of the raw data. Below we count the length of each sequence and plot the distribution. You will see that this is very problematic. The longest sequence in the data is 36,958 time steps!
Now that we’ve examined our data, we need to extract it from the CSV and transform it into sequence data. DataVec and Spark make this easy to use for us.
Using DataVec’s Schema class we define the schema of the data and their columns. Alternatively, if you have a sample file of the data you can also use the InferredSchema class. Afterwards, we can build a TransformProcess that removes any unwanted fields and uses a comparison of timestamps to create sequences for each unique ship in the AIS data.
Once we’re certain that the schema and transformations are what we want, we can read the CSV into a Spark RDD and execute our transformation with DataVec. First, we convert the data to a sequence with convertToSequence() and a numerical comparator to sort by timestamp. Then we apply a window function to each sequence to reduce those windows to a single value. This helps reduce the variability in sequence lengths, which will be problematic when we go to train our autoencoder.
If you want to use the Scala-style method of programming, you can switch back and forth between the Scala and Java APIs for the Spark RDD. Calling .rdd on a JavaRDD will return a regular RDD Scala class. If you prefer the Java API, call toJavaRDD() on a RDD.
To reduce the complexity of this tutorial, we will be omitting anomalous trajectories. In the analysis above you’ll see that there is a significant number of trajectories with invalid positions. Latitude and longitude coordinates do not exceed the -90,90 and -180,180 ranges respectively; therefore, we filter them. Additionally, many of the trajectories only include a handful of positions - we will eliminate sequences that are too short for meaningful representation.
Once you have finished preprocessing your dataset, you have a couple options to serialize your dataset before feeding it to your autoencoder network via an iterator. This applies to both unsupervised and supervised learning.
Save to Hadoop Map File. This serializes the dataset to the hadoop map file format and writes it to disk. You can do this whether your training network will be on a local, single node or distributed across multiple nodes via Spark. The advantage here is you can preprocess your dataset once, and read from the map file as much as necessary.
Pass the RDD to a RecordReaderMultiDataSetIterator. If you prefer to read your dataset directly from Spark, you can pass your RDD to a RecordReaderMultiDataSetIterator. The SparkSourceDummyReader class acts as a placeholder for each source of records. This process will convert the records to a MultiDataSet which can then be passed to a distributed neural network such as SparkComputationGraph.
Serialize to another format. There are other options for serializing a dataset which will not be discussed here. They include saving the INDArray data in a compressed format on disk or using a proprietary method you create yourself.
This example uses method 1 above. We’ll assume you have a single machine instance for training your network. Note: you can always mix architectures for preprocessing and training (Spark vs. GPU cluster). It really depends on what hardware you have available.
Now that we’ve saved our dataset to a Hadoop Map File, we need to set up a RecordReader and iterator that will read our saved sequences and feed them to our autoencoder. Conveniently, if you have already saved your data to disk, you can run this code block (and remaining code blocks) as much as you want without preprocessing the dataset again.
Now that we’ve prepared our data, we must construct the sequence-to-sequence autoencoder. The configuration is quite similar to the autoencoders in other tutorials, except layers primarily use LSTMs. Note that in this architecture we use a DuplicateToTimeSeriesVertex between our encoder and decoder. This allows us to iteratively generate while each time step will get the same input but a different hidden state.
Now that the network configruation is set up and instantiated along with our iterators, training takes just a few lines of code. Earlier we attached a ScoreIterationListener to the model by using the setListeners() method. Depending on the browser you are using to run this notebook, you can open the debugger/inspector to view listener output. This output is redirected to the console since the internals of Deeplearning4j use SL4J for logging, and the output is being redirected by Zeppelin. This is a good thing since it can reduce clutter in notebooks.
After each epoch, we will evaluate how well the network is learning by using the evaluate() method. Although here we only use accuracy() and precision(), it is strongly recommended you learn how to do advanced evaluation with ROC curves and understand the output from a confusion matrix.
Deeplearning4j has a built-in MultipleEpochsIterator that automatically handles multiple epochs of training. Alternatively, if you instead want to handle per-epoch events you can either use an EarlyStoppingGraphTrainer which listens for scoring events, or wrap net.fit() in a for-loop yourself.
Below, we manually create a for- loop since our iterator requires a more complex MultiDataSet. This is because our seq2seq autoencoder uses multiple inputs/outputs.
The autoencoder here has been tuned to converge with an average reconstruction error of approximately 2% when trained for 35+ epochs.
At this point, you’ve invested a lot of time and computation building your autoencoder. Saving it to disk and restoring it is quite simple.
Below we build a loop to visualize just how well our autoencoder is able to reconstruct the original sequences. After forwarding a single example, we score the reconstruction and then compare the original array to the reconstructed array. Note that we need to do some string formatting, otherwise when we try to print the array we will get garbled output
this is actually a reference to the array object in memory.
Now that the network has been trained, we will extract the encoder from the network. This is so we can construct a new network for exclusive representation encoding.
Homestretch! We’re now able to take the compressed representations of our trajectories and start to cluster them together. As mentioned earlier, a non-K clustering algorithm is preferable.
The Smile Scala library has a number of clustering methods already available and we’ll be using it for grouping our trajectories.
Visualizing the clusters requires one extra step. Our seq2seq autoencoder produces representations that are higher than 2 or 3 dimensions, meaning you will need to use an algorithm such as t-SNE to further reduce the dimensionality and generate “coordinates” that can be used for plotting. The pipeline would first involve clustering your encoded representations with G-means, then feeding the output to t-SNE to reduce the dimensionality of each representation so it can be plotted.
You may be thinking, “do these clusters make sense?” This is where further exploration is required. You’ll need to go back to your clusters, identify the ships belonging to each one, and compare the ships within each cluster. If your encoder and clustering pipeline worked, you’ll notice patterns such as:
ships crossing the English channel are grouped together
boats parked in marinas also cluster together
trans- atlantic ships also tend to cluster together
Train FaceNet Using Center Loss
Deep learning is the de facto standard for face recognition. In 2015, Google researchers published FaceNet: A Unified Embedding for Face Recognition and Clustering, which set a new record for accuracy of 99.63% on the LFW dataset. An important aspect of FaceNet is that it made face recognition more practical by using the embeddings to learn a mapping of face features to a compact Euclidean space (basically, you input an image and get a small 1D array from the network). FaceNet was an adapted version of an Inception-style network.
Around the same time FaceNet was being developed, other research groups were making significant advances in facial recognition. DeepID3, for example, achieved impressive results. Oxford’s Visual Geometry Group published Deep Face Recognition. Note that the Deep Face Recognition paper has a comparison of previous papers, and one key factor in FaceNet is the number of images used to train the network: 200 million.
FaceNet is difficult to train, partially because of how it uses triplet loss. This required exotic architectures that either set up three models in tandem, or required stacking of examples and unstacking with additional nodes to calculate loss based on euclidean similarity. A Discriminative Feature Learning Approach for Deep Face Recognition introduced center loss, a promising technique that added an intraclass component to a training loss function.
The advantage of training embeddings with center loss is that an exotic architecture is no longer required. In addition, because hardware is better utilized, the amount of time it takes to train embeddings is much shorter. One important distinction when using center loss vs. a triplet loss architecture is that a center loss layer stores its own parameters. These parameters calculate the intraclass “center” of all examples for each label.
Using Deeplearning4j, you will learn how to train embeddings for facial recognition and transfer parameters to a new network that uses the embeddings for feed forward. The network will be built using ComputationGraph (Inception-type networks require multiple nodes) via the OpenFace NN4.Small2 variant, which is a hand-tuned, parameter-minimized model of FaceNet.
Because Inception networks are large, we will use the Deeplearning4j model zoo to help build our network.
We are using a minified version of the full FaceNet network to reduce the hardware requirements. Below, we use the FaceNetHelper class for some of the Inception blocks, where parameters have been unchanged from the larger version.
To see that Center Loss if already in the model configuration, you can print a string table of all layers in the network. Use the summary() method to get a complete summary of all layers and parameters. You’ll see that our network here has over 5 million parameters, this is still quite low compared to advanced ImageNet configurations, but will still be taxing on your hardware.
The LFWDataSetIterator, like most of the Deeplearning4j built-in iterators, extends the DataSetIterator class. This API allows for the simple instantiation of datasets and automatic downloading of data in the background. If you are unfamiliar with using DL4J’s built-in iterators, there’s a tutorial describing their usage.
With the network configruation is set up and instantiated along with the LFW test/train iterators, training takes just a few lines of code. Since we have a labelled dataset and are using center loss, this is considered “classifier training” and is a supervised learning process. Earlier we attached a ScoreIterationListener to the model by using the setListeners() method. Its output is printed to the console since the internals of Deeplearning4j use SL4J for logging.
After each epoch, we will evaluate how well the network is learning by using the evaluate() method. Although in this example we only use accuracy() and precision(), it is strongly recommended you perform advanced evaluation with ROC curves and understand the output of a confusion matrix.
Now that the network has been trained, using the embeddings requires removing the center loss output layer. Deeplearning4j has a native transfer learning API to assist.
In this tutorial we will use a neural network to forecast daily sea temperatures. This tutorial will be similar to tutorial . Recall, that the data consists of 2-dimensional temperature grids of 8 seas: Bengal, Korean, Black, Mediterranean, Arabian, Japan, Bohai, and Okhotsk Seas from 1981 to 2017. The raw data was taken from the Earth System Research Laboratory (https://www.esrl.noaa.gov/psd/) and preprocessed into CSV files. Each example consists of fifty 2-dimensional temperature grids, and every grid is represented by a single row in a CSV file. Thus, each sequence is represented by a CSV file with 50 rows.
For this task, we will use a convolutional LSTM neural network to forecast 10 days worth of sea temperatures following a given sequence of temperature grids. The network will be trained similarly to the network trained tutorial 15. But the evaluation will be handled differently (applied only to the 10 days following the sequences).
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory
We will then extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directories, and copy the files from the tar.gz file.
Next we will convert the raw data (csv files) into DataSetIterators, which will be fed into a neural network. Our training data will have 1600 examples which will be represented by a single DataSetIterator, and the testing data will have 136 examples which will be represented by a separate DataSetIterator. The temperatures of the 10 days following the sequences in the training and testing data will be contained in a separate DataSetIterator as well.
We first initialize CSVSequenceRecordReaders, which will parse the raw data into record-like format. Then the SequenceRecordReaderDataSetIterators can be created using the RecordReaders. Since each example has exactly 50 timesteps, an alignment mode of equal length is needed. Note also that this is a regression- based task and not a classification one.
The next task is to initialize the parameters for the convolutional LSTM neural network and then set up the neural network configuration.
In the neural network configuraiton we will use the convolutional layer, subsampling layer, LSTM layer, and output layer in success. In order to do this, we need to use the RnnToCnnPreProcessor and CnnToRnnPreprocessor. The RnnToCnnPreProcessor is used to reshape the 3-dimensional input from [batch size, height x width of grid, time series length ] into a 4 dimensional shape [number of examples x time series length , channels, width, height] which is suitable as input to a convolutional layer. The CnnToRnnPreProcessor is then used in a later layer to convert this convolutional shape back to the original 3-dimensional shape.
To train the model, we use 15 epochs and call the fit method of the MultiLayerNetwork.
We will now evaluate our trained model. Note that we will use RegressionEvaluation, since our task is a regression and not a classification task. We will only evaluate the model using the temperature of the 10 days following the given sequence of daily temperatures and not on the temperatures of the days in the sequence. This will be done using the rnnTimeStep() method of the MultiLayerNetwork.
Here we print out the evaluation statistics.
In previous tutorials we learned how to configure different neural networks such as feed forward, convolutional, and recurrent networks. The type of neural network is determined by the type of hidden layers they contain. For example, feed forward neural networks are comprised of dense layers, while recurrent neural networks can include Graves LSTM (long short-term memory) layers. In this tutorial we will learn how to use combinations of different layers in a single neural network using the MultiLayerNetwork class of deeplearning4j (DL4J). Additionally, we will learn how to use preprocess our data to more efficiently train the neural networks. The MNIST dataset (images of handwritten digits) will be used as an example for a convolutional network.
Now that everything needed is imported, we can start by configuring a convolutional neural network for a MultiLayerNetwork. This network will consist of two convolutional layers, two max pooling layers, one dense layer, and an output layer. This is easy to do using DL4J’s functionality; we simply add a dense layer after the max pooling layer to convert the output into vectorized form before passing it to the output layer. The neural network will then attempt to classify an observation using the vectorized data in the output layer.
The only tricky part is getting the dimensions of the input to the dense layer correctly after the convolutional and max pooling layers. Note that we first start off with a 28 by 28 matrix and after applying the convolution layer with a 5 by 5 kernel we end up with twenty 24 by 24 matrices. Once the input is passed through the max pooling layer with a 2 by 2 kernel and a stride of 2 by 2, we end up with twenty 12 by 12 matrices. After the second convolutional layer with a 5 by 5 kernel, we end up with fifty 8 by 8 matrices. This output is reduced to fifty 4 by 4 matrices after the second max pooling layer which has the same kernel size and stride of the first max pooling layer. To vectorize these final matrices, we require an input of dimension 5044 or 800 in the dense layer.
Before training the neural network, we will instantiate built-in DataSetIterators for the MNIST data. One example of data preprocessing is scaling the data. The data we are using in raw form are greyscale images, which are represented by a single matrix filled with integer values from 0 to 255. A 0 value indicates a black pixel, while a 1 value indicates a white pixel. It is helpful to scale the image pixel value from 0 to 1 instead of from 0 to 255. To do this, the ImagePreProcessingScaler class is used directly on the MnistDataSetIterators. Note that this process is typtical for data preprocessing. Once this is done, we are ready to train the neural network.
To train the neural network, we use 5 epochs or complete passes through the training set by simply calling the fit method.
Lastly, we use the test split of the data to evaluate how well our final model performs on data it has never seen. We can see that the model performs pretty well using only 5 epochs!
In this tutorial we will use a neural network to forecast daily sea temperatures. The data consists of 2-dimensional temperature grids of 8 seas: Bengal, Korean, Black, Mediterranean, Arabian, Japan, Bohai, and Okhotsk Seas from 1981 to 2017. The raw data was taken from the Earth System Research Laboratory (https://www.esrl.noaa.gov/psd/) and preprocessed into CSV file. Each example consists of fifty 2-dimensional temperature grids, and every grid is represented by a single row in a CSV file. Thus, each sequence is represented by a CSV file with 50 rows.
For this task, we will use a convolutional LSTM neural network to forecast next-day sea temperatures for a given sequence of temperature grids. Recall, a convolutional network is most often used for image data like the MNIST dataset (dataset of handwritten images). A convolutional network is appropriate for this type of gridded data, since each point in the 2-dimensional grid is related to its neighbor points. Furthermore, the data is sequential, and each temperature grid is related to the previous grids. Because of these long and short term dependencies, a LSTM is fitting for this task too. For these two reasons, we will combine the aspects from these two different neural network architectures into a single convolutional LSTM network.
For more information on the convolutional LSTM network structure, see
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory.
We will then extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directories, and copy the files from the tar.gz file.
Next we will convert the raw data (csv files) into DataSetIterators, which will be fed into a neural network. Our training data will have 1700 examples which will be represented by a single DataSetIterator, and the testing data will have 404 examples which will be represented by a separate DataSet Iterator.
We first initialize CSVSequenceRecordReaders, which will parse the raw data into record-like format. Then the SequenceRecordReaderDataSetIterators can be created using the RecordReaders. Since each example has exaclty 50 timesteps, an alignment mode of equal length is needed. Note also that this is a regression- based task and not a classification one.
The next task is to initialize the parameters for the convolutional LSTM neural network and then set up the neural network configuration.
In the neural network configuraiton we will use the convolutional layer, LSTM layer, and output layer in success. In order to do this, we need to use the RnnToCnnPreProcessor and CnnToRnnPreprocessor. The RnnToCnnPreProcessor is used to reshape the 3-dimensional input from [batch size, height x width of grid, time series length ] into a 4 dimensional shape [number of examples x time series length , channels, width, height] which is suitable as input to a convolutional layer. The CnnToRnnPreProcessor is then used in a later layer to convert this convolutional shape back to the original 3-dimensional shape.
To train the model, we use 25 epochs and simply call the fit method of the MultiLayerNetwork.
We will now evaluate our trained model. Note that we will use RegressionEvaluation, since our task is a regression and not a classification task.
In this tutorial we will use a LSTM neural network to predict instacart users’ purchasing behavior given a history of their past orders. The data originially comes from a Kaggle challenge (). We first removed users that only made 1 order using the instacart app and then took 5000 users out of the remaining to be part of the data for this tutorial.
For each order, we have information on the product the user purchased. For example, there is information on the product name, what aisle it is found in, and the department it falls under. To construct features, we extracted indicators representing whether or not a user purchased a product in the given aisles for each order. In total there are 134 aisles. The targets were whether or not a user will buy a product in the breakfast department in the next order. We also used auxiliary targets to train this LSTM. The auxiliary targets were whether or not a user will buy a product in the dairy department in the next order.
We suspect that a LSTM will be effective for this task, because of the temporal dependencies in the data.
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory.
We will then extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directories, and copy the files from the tar.gz file.
Next we will convert the raw data (csv files) into DataSetIterators, which will be fed into a neural network. Our training data will have 4000 examples which will be represented by a single DataSetIterator, and the testing data will have 1000 examples which will be represented by a separate DataSetIterator.
We first initialize CSVSequenceRecordReaders, which will parse the raw data into record-like format. Because we will be using multitask learning, we will use two outputs. Thus we need three RecordReaders in total: one for the input, another for the first target, and the last for the second target. Next, we will need the RecordreaderMultiDataSetIterator, since we now have two outputs. We can add our SequenceRecordReaders using the addSequenceReader methods and specify the input and both outputs. The ALIGN_END alignment mode is used, since the sequences for each example vary in length.
We will create DataSetIterators for both the training data and the test data.
The next task is to set up the neural network configuration. We see below that the ComputationGraph class is used to create a LSTM with two outputs. We can set the outputs using the setOutputs method of the NeuralNetConfiguraitonBuilder. One GravesLSTM layer and two RnnOutputLayers will be used. We will also set other hyperparameters of the model, such as dropout, weight initialization, updaters, and activation functions.
We must then initialize the neural network.
To train the model, we use 5 epochs with a simple call to the fit method of the ComputationGraph.
We will now evaluate our trained model on the original task, which was predicting whether or not a user will purchase a product in the breakfast department. Note that we will use the area under the curve (AUC) metric of the ROC curve.
We achieve a AUC of 0.75!
In this tutorial, we will learn how to apply a long-short term memory (LSTM) neural network to a medical time series problem. The data used comes from 4000 intensive care unit (ICU) patients and the goal is to predict the mortality of patients using 6 general descriptor features, such as age, gender, and weight along with 37 sequential features, such as cholesterol level, temperature, pH, and glucose level. Each patient has multiple measurements of the sequential features, with patients having a different amount of measurements taken. Furthermore, the time between measurements also differ among patients as well.
A LSTM is well suited for this type of problem due to the sequential nature of the data. In addition, LSTM networks avoid vanishing and exploding gradients and are able to effectively capture long term dependencies due to its cell state, a feature not present in typical recurrent networks.
Now that we have imported everything needed to run this tutorial, we will start with obtaining the data and then converting the data into a format a neural network can understand.
The data is contained in a compressed tar.gz file. We will have to download the data from the url below and then extract csv files containing the ICU data. Each patient will have a separate csv file for the features and labels. The features will be contained in a directory called sequence and the labels will be contained in a directory called mortality. The features are contained in a single csv file with the columns representing the features and the rows representing different time steps. The labels are contained in a single csv file which contains a value of 0 indicating death and a value of 1 indicating survival.
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory.
Next, we must extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directory, and copy the files into our temporary directory.
Our next goal is to convert the raw data (csv files) into a DataSetIterator, which can then be fed into a neural network for training. Our training data will have 3200 examples which will be represented by a single DataSetIterator, and the testing data will have 800 examples which will be represented by a separate DataSet Iterator.
In order to obtain DataSetIterators, we must first initialize CSVSequenceRecordReaders, which will parse the raw data into record-like format. We will first set the directories for the features and labels and initialize the CSVSequenceRecordReaders.
Now we can finally configure and then initialize the neural network for this problem. We will be using the ComputationGraph class of DL4J.
To train the neural network, we simply call the fit method of the ComputationGraph on the trainData DataSetIterator and also pass how many epochs it should train for.
Finally, we can evaluate the model with the testing split using the AUC (area under the curve metric ) using a ROC curve. A randomly guessing model will have an AUC close to 0.50, while a perfect model will achieve an AUC of 1.00
We see that this model achieves an AUC on the test set of 0.69!
This tutorial will be similar to the . The only difference is that we will not use multitasking to train our neural network. Recall the data originially comes from a Kaggle challenge (). We removed users that only made 1 order using the instacart app and then took 5000 users out of the remaining to be part of the data for this tutorial.
For each order, we have information on the product the user purchased. For example, there is information on the product name, what aisle it is found in, and the department it falls under. To construct features, we extracted indicators representing whether or not a user purchased a product in the given aisles for each order. In total there are 134 aisles. The targets were whether or not a user will buy a product in the breakfast department in the next order. As mentioned, we will not use any auxiliary targets.
Because of temporal dependencies within the data, we used a LSTM network for our model.
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory.
We will then extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directories, and copy the files from the tar.gz file.
Next we will convert the raw data (csv files) into DataSetIterators, which will be fed into a neural network. Our training data will have 4000 examples which will be represented by a single DataSetIterator, and the testing data will have 1000 examples which will be represented by a separate DataSetIterator.
We first initialize CSVSequenceRecordReaders, which will parse the raw data into record-like format. Then the SequenceRecordReaderDataSetIterators can be created using the RecordReaders. Since each example has sequences of different lengths, an alignment mode of align end is needed.
The next task is to set up the neural network configuration. We will use a MultiLayerNetwork and the configuration will be similar to the multitask model from before. Again we use one GravesLSTM layer but this time only one RnnOutputLayer.
We must then initialize the neural network.
To train the model, we use 5 epochs with a simple call to the fit method of the MultiLayerNetwork.
We will now evaluate our trained model. Note that we will use the area under the curve (AUC) metric of the ROC curve.
We achieve a AUC of 0.64!
In this tutorial, we will apply a neural network model to a cloud detection application using satellite imaging data. The data is from NASA’s Multi-angle Imaging SpectroRadiometer (MISR) which was launched in 1999. The MISR has nine cameras that view the Earth from nine different directions which allows the MISR to measure elevations and angular radiance signatures of objects. We will use the radiances measured from the MISR and features developed using domain expertise to learn to detect whether clouds are present in polar regions. This is a particularly challenging task due to the snow and ice covering the ground surfaces.
The data is taken from MISR measurements and expert features of 3 images of polar regions. For each location in the grid, there is an expert label whether or not clouds are present and 8 features (radiances + expert labels). Data from two images will comprise the training set and the left out image is in the test set.
The data can be found in a tar.gz file located at the url provided below in the next cell. It is organized into two directories (train and test). In each directory there are five subdirectories: n1, n2, n3, n4, and n5. The data in n1 contains expert features and the label pertaining to a particular location in an image. n2, n3, n4, and n5 contain the expert features corresponding to the nearest locations to the original location.
We will additionally use features from a location’s nearest neighbors as features to feed into our model, because there are dependencies across neighboring locations. In other words, if a location’s neighbors have a positive cloud label, it is more likely for the original location to have a positive cloud label as well. The reverse also applies as well.
To download the data, we will create a temporary directory that will store the data files, extract the tar.gz file from the url, and place it in the specified directory.
Next, we must extract the data from the tar.gz file, recreate directories within the tar.gz file into our temporary directory, and copy the files into our temporary directory.
Our next goal is to convert the raw data (csv files) into a DataSetIterator, which can then be fed into a neural network for training. We will first obtain the paths containing the raw data, which is in csv file format.
We then will create two DataSetIterators to feed the data into a neural network. But first, we will initialize CSVRecordReaders to parse the raw data and convert it to record-like format. We create separate CSVRecordReaders for the original location and each nearest neighbor. Since the data is contained in separate RecordReaders, we will use a RecordReaderMultiDataSetIterator, which allows for multiple inputs or outputs. We then add the RecordReaders to the DataSetIterator using the addReader method of the DataSetIterator.Builder() class. We specify the inputs using the addInput method and the label using the addOutputOneHot method.
The same process is applied to the testing data.
Now that the DataSetIterators are initialized, we can now specify the configuration of the neural network. We will ultimately use a ComputationGraph since we will have multiple inputs to the network. MultiLayerNetworks cannot be used when there are multiple inputs and/or outputs.
To specify the network architecture and the hyperparameters, we use the NeuralNetConfiguraiton.Builder class. We can add each input using the addLayer method of the class. Because the inputs are separate, the addVertex method is used to add a MergeVertex to the network. This vertex will merge the outputs from the previous input layers into a combined representation. Finally, a fully connected layer is applied to the merged output, which passes the activations to the final output layer.
The other hyperparameters, such as the optimization algorithm, updater, number of hidden nodes, and etc are also specified in this block of code as well.
We are now ready to train our model. We initialize our ComptutationGraph and train over the number of epochs with a call to the fit method of the ComputationGraph to train our specified model.
To evaluate our model, we simply use the evaluateROC method of the ComptuationGraph class.
Finally we can print out the area under the curve (AUC) metric!
Next, we can initialize the SequenceRecordReaderDataSetIterator using the previously created CSVSequenceRecordReaders. We will use an alignment mode of ALIGN_END. This alignment mode is needed due to the fact that the number of time steps differs between different patients. Because the mortality label is always at the end of the sequence, we need all the sequences aligned so that the time step with the mortality label is the last time step for all patients. For a more in depth explanation of alignment modes, see .







